Redis 主从架构
在Redis主从架构下,一般是主备,即主节点提供读写操作,从节点作为备份。
也可以额外写代码做读写分离,即主节点提供写操作,从节点提供读操作和作为备份。
主从架构搭建
主节点配置(redis.conf):
# 可选配置
port 6379
logfile "redis.log" # 日志文件
dir /usr/local/redis/data/master # 数据存放目录
# 关键配置
#bind 127.0.0.1 -::1 # 注释掉这一行,让Redis监听所有网络接口(网卡)
bind 127.0.0.1 120.55.167.193 # 也可以不注释:除了本地回环接口,额外监听内网IP对应接口
protected-mode no # 关闭保护模式(如开启的话,只有本机才可以访问redis)从节点配置(redis.conf):
# 可选配置
port 6379
pidfile /var/run/redis_slave01.pid # 用于写入进程id的文件
logfile "slave01.log" # 日志文件
dir /usr/local/redis/data/slave01 # 用于存放数据的目录
# 关键配置
replicaof 120.55.167.193 6379 # 主节点的ip和端口
replica-read-only yes # 从节点只读从节点同步日志:
info命令查看节点信息:
Server
Clients
Memory
Persistence
Stats
Replication
CPU
Modules
Errorstats
Cluster
Keyspace
info replication命令只看主从信息:
# Replication
role:slave
master_host:120.55.167.193
master_port:6379
master_link_status:up
master_last_io_seconds_ago:5
master_sync_in_progress:0
slave_read_repl_offset:3597
slave_repl_offset:3597
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:c11841a8646a16492cb873de3e8654c7f8eb80aa
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:3597
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:15
repl_backlog_histlen:3583Redis 主从工作原理
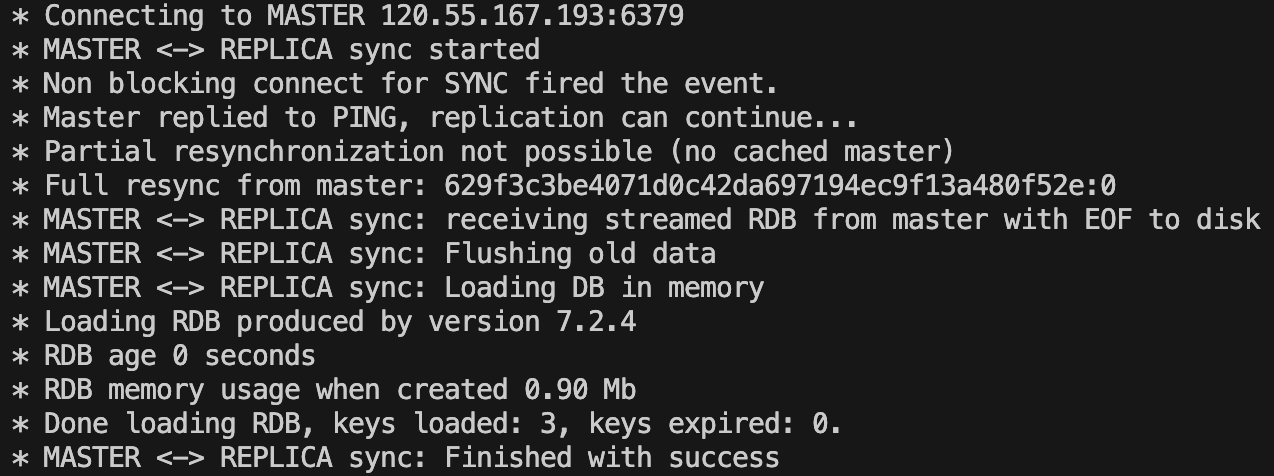
全量复制:
.png)
为什么一开始使用RDB同步数据?
因为RDB恢复数据比较快,并且不管有没有开启RDB持久化,一开始都会使用RDB同步数据。
部分复制:
如果同步数据的过程中,从节点跟主节点的连接断开一段时间后又重新连接上了,会优先尝试获取在连接断开期间丢失的命令。
.png)
epl buffer 和 repl backlog buffer 区别?
repl buffer 在全量复制阶段使用,主节点会给每个从节点分配一个 repl buffer,用于存放从节点加载RDB数据过程中主节点收到的写命令
repl backlog buffer 在增量阶段使用,主节点只有一个 repl backlog buffer,用于存放主节点最近收到的写命令
如果 repl backlog buffer 满了,由于它是环形结构,会覆盖之前的数据(通过repl-backlog-size修改大小,默认1mb)
如果 repl buffer 满了或者长时间占用一定的大小,会断开连接,从节点重新连接,重新开始全量复制(通过client-output-buffer-limit slave修改大小)
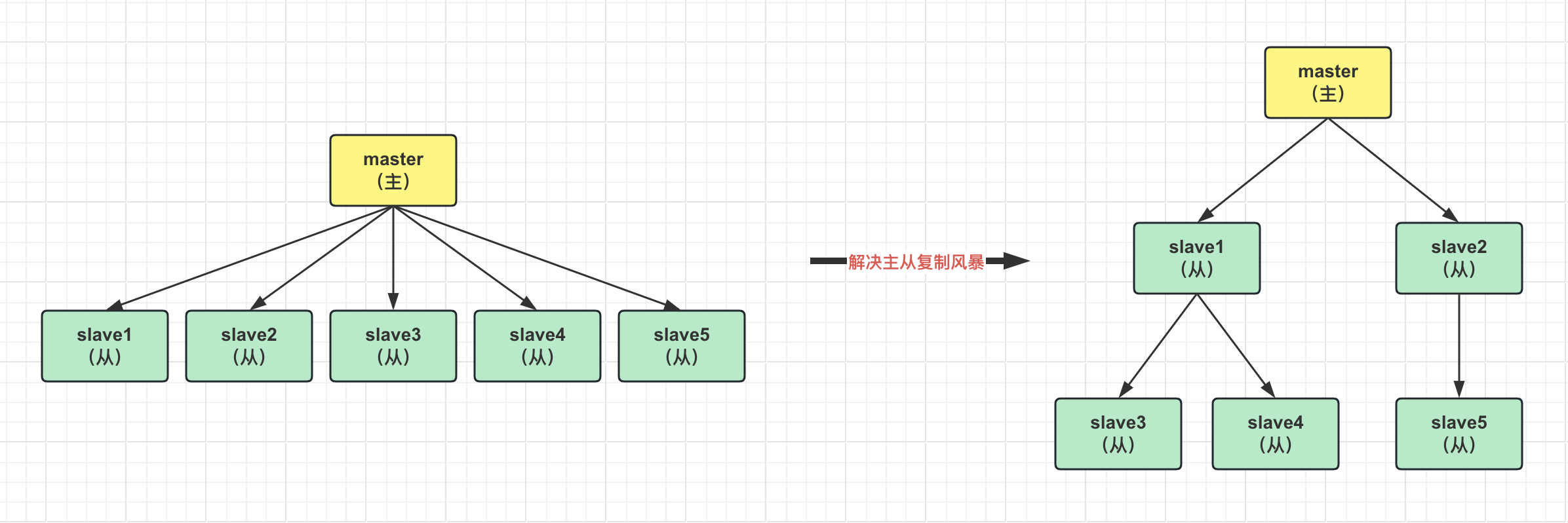
主从复制风暴:
如果有很多从节点同时同步主节点的数据,会导致主节点压力过大,这就是主从复制风暴。
可以通过下面的架构解决主从复制风暴,让部分从节点跟从节点同步数据:
使用Jedis验证主从架构
(1) 添加Jedis依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.1.3</version>
</dependency>(2) 访问Redis
// jedis 连接池配置
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMinIdle(5);
// jedis 连接池(timeout=3000 既是连接超时也是读写超时)
try (JedisPool jedisPool = new JedisPool(jedisPoolConfig, "120.55.167.193", 6379, 3000, null)) {
Jedis jedis = jedisPool.getResource();
System.out.println(jedis.set("idea", "520")); // OK
System.out.println(jedis.get("idea")); // 520
}(3) 检查从节点是否同步
Redis管道
Redis管道用来批量执行命令,即一个请求执行多条命令,目的是减少网络开销。(不是原子的)
Pipeline pipeline = jedis.pipelined();
for (int i = 1; i <= 10; i++) {
pipeline.set("xjj" + i, String.valueOf(i));
}
System.out.println(pipeline.syncAndReturnAll());管道会依次执行其中的命令,管道前面的命令执行失败,不会影响后面的命令继续执行。
Redis Lua脚本
Redis支持使用Lua脚本以原子方式执行多条命令。
使用Lua脚本的好处:
减少网络开销:类似管道,也可以批量执行命令
原子操作:Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入,
替代Redis事务功能:Redis自带事务能力有缺陷,不支持回滚,而Redis的Lua脚本实现了常规的事务功能,支持报错回滚。
Redis内置有Lua解释器,可以使用eval命令对Lua脚本进行求值:`eval <script> <key_num> key [key…] arg [arg…]`(key_num表示用到的key的数量,在Lua脚本中可以通过KEYS数组获取key,索引从1开始,key后面的其他参数通过ARGV数组访问,索引也是从1开始)
注意:避免在Lua脚本中出现死循环和耗时操作,否则会阻塞其他命令。
下面用Lua脚本实现一个商品减库存的原子操作:
local stock = redis.call('get', KEYS[1])
local a = tonumber(stock)
local b = tonumber(ARGV[1])
if a >= b then
redis.call('set', KEYS[1], a - b)
return 1
end
return 0在Jedis中使用Lua脚本:
