Redis 高并发缓存架构
锁优化
(1) 缩小锁粒度:加锁粒度要小,只给必要的代码加锁
(2) 使用分段锁
举例:
将锁 stock:product:101=1000 分成 10 段:
stock:product:101:1=100, stock:product:101:2=100, …, stock:product:101:10=100
这样可以同时有 10 个线程执行减库存的逻辑,相当于性能提升了 10 倍。
参考ConcurrentHashMap的分段实现
(3) 使用读写锁:适用于数据库读多写少的场景,读读可以并行执行(相当于无锁),读写和写写只能串行执行
使用举例:
private Product getProductFromDB(String id) {
Product product = null;
String cacheKey = PRODUCT_CACHE_PREFIX + id;
// 使用读写锁优化
RReadWriteLock productUpdateLock = redissonClient.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + id);
// 查询数据库操作,使用读锁(允许多个线程并发执行:查询数据库+更新缓存)
RLock readLock = productUpdateLock.readLock();
readLock.lock();
try {
product = productDao.query(id);
if (product != null) {
stringRedisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
} else {
stringRedisTemplate.opsForValue().set(cacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);
}
} catch (Exception e) {
// handle exception...
} finally {
readLock.unlock();
}
return product;
}
public Product updateProduct(Product product) {
Product productResult = null;
// 使用读写锁优化
RReadWriteLock productUpdateLock = redissonClient.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + product.getId());
// 更新数据库操作,使用写锁
RLock writeLock = productUpdateLock.writeLock();
writeLock.lock();
try {
productResult = productDao.update(product);
stringRedisTemplate.delete(PRODUCT_CACHE_PREFIX + product.getId());
} catch (Exception e) {
// handle exception...
} finally {
writeLock.unlock();
}
return productResult;
} (4) 串行转并发:在有些场景,允许分布式锁串行转并发,如Redisson使用tryLock()加锁
public Object queryProduct(String id) {
Product product = getProductFromCache(id);
if (product != null) {
return product;
}
RLock productCacheRebuildLock = redissonClient.getLock(LOCK_PRODUCT_CACHE_REBUILD_PREFIX + id);
try {
// 串行转并发:预估第一个抢到锁的线程要执行的时间,在这个预估时间之后,将所有线程放开,理想情况下缓存已经重建,因此这些放开的线程可获取到缓存后直接返回(高并发下可权衡使用)
productCacheRebuildLock.tryLock(1, TimeUnit.SECONDS); // tryLock()指定时间后,即使没获取到锁(返回false),线程也会往下执行
product = getProductFromCache(id);
if (product != null) {
return product;
}
product = getProductFromDB(id);
} catch (Exception e) {
// handle exception...
} finally {
productCacheRebuildLock.unlock();
}
return product;
}缓存优化
(1) 设置缓存时加上超时时间,命中缓存时给缓存延期(简易版数据冷热分离)
这样的话,热点数据可以常驻缓存,冷门数据的缓存会失效,可以节省内存资源
(2) 多级缓存
在单个key大于10w并发请求的场景下,会超过Redis的处理能力,这时候可以限流或者使用多级缓存。
下面是一个常见的多级缓存架构:
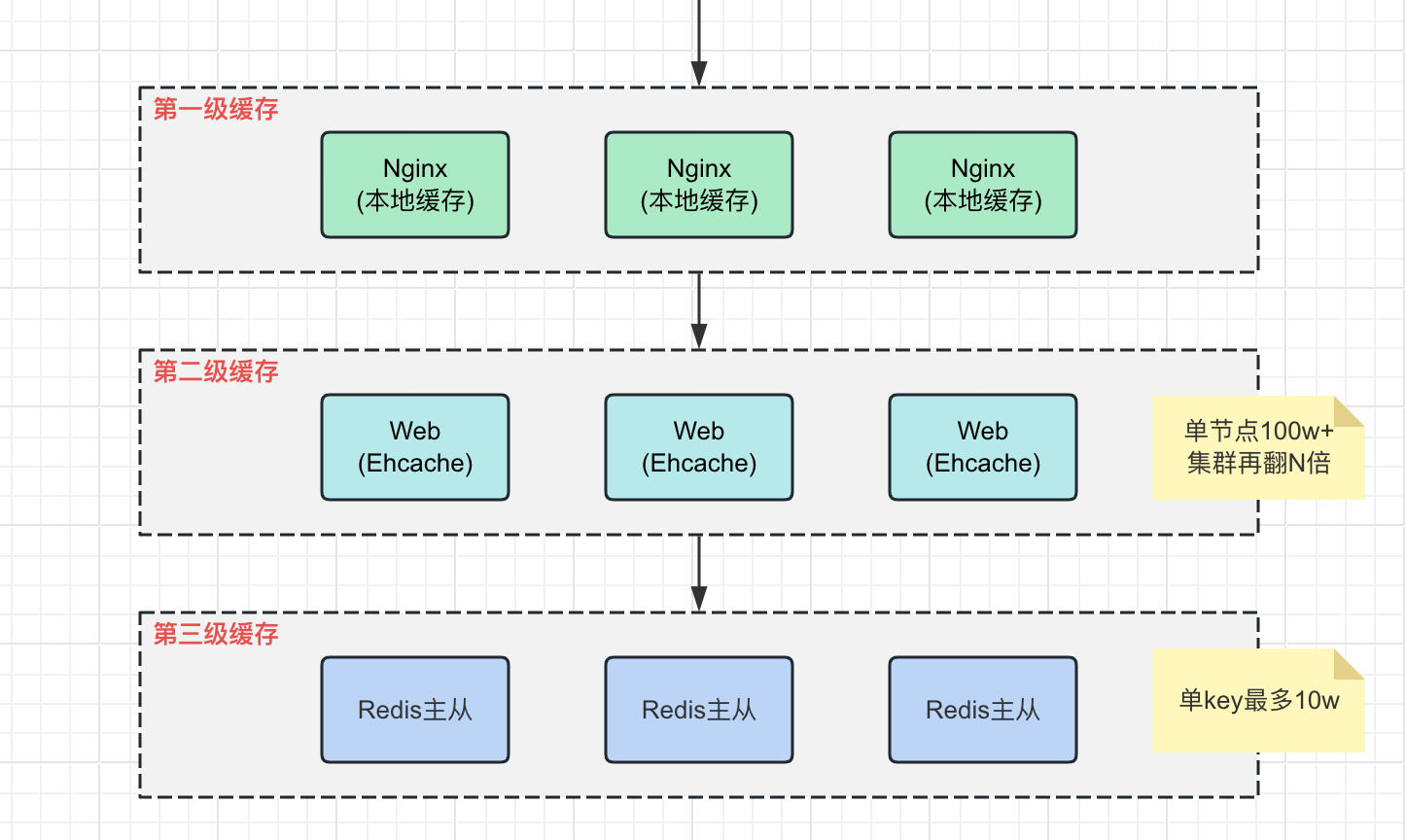
常见缓存问题
下面以查询商品为例,展示如何解决上面列举的常见缓存问题:
public Object queryProduct(String id) {
// 首次查询缓存
Product product = getProductFromCache(id);
if (product != null) {
return product;
}
// 加锁(用于并发重建热点缓存时,解决缓存击穿问题)
RLock productCacheRebuildLock = redissonClient.getLock(LOCK_PRODUCT_CACHE_REBUILD_PREFIX + id);
try {
productCacheRebuildLock.lock();
// 串行转并发:预估第一个抢到锁的线程要执行的时间,在这个预估时间之后,将所有线程放开,理想情况下缓存已经重建,因此这些放开的线程可获取到缓存后直接返回(高并发下可权衡使用)
// productCacheRebuildLock.tryLock(1, TimeUnit.SECONDS); // tryLock()指定时间后,即使没获取到锁(返回false),线程也会往下执行
// 再次查询缓存
product = getProductFromCache(id);
if (product != null) {
return product;
}
// 查数据库(只有第一个抢到锁的线程会查询数据库,解决了缓存击穿问题)
product = getProductFromDB(id);
} catch (Exception e) {
// handle exception...
} finally {
productCacheRebuildLock.unlock();
}
return product;
}
private Product getProductFromCache(String id) {
String cacheKey = PRODUCT_CACHE_PREFIX + id;
String productStr = stringRedisTemplate.opsForValue().get(cacheKey);
if (productStr != null) {
if (EMPTY_CACHE.equals(productStr)) {
stringRedisTemplate.expire(cacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);
}
// 读延期:刷新缓存过期时间(使得热点数据缓存不失效)
stringRedisTemplate.expire(cacheKey, genProductCacheTimeout(), TimeUnit.SECONDS);
return JSON.parseObject(productStr, Product.class);
}
return null;
}
private Product getProductFromDB(String id) {
Product product = null;
String cacheKey = PRODUCT_CACHE_PREFIX + id;
// 加锁(用于更新缓存时,解决双写不一致问题)
RReadWriteLock productUpdateLock = redissonClient.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + id); // 使用读写锁优化
RLock readLock = productUpdateLock.readLock(); // 查询数据库操作,使用读锁(允许多个线程并发执行:查询数据库+更新缓存)
readLock.lock();
try {
product = productDao.query(id);
if (product != null) {
// 更新缓存(使用随机缓存过期时间,解决了缓存雪崩问题)
stringRedisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
} else {
// 缓存空值(解决缓存穿透问题)
stringRedisTemplate.opsForValue().set(cacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);
}
} catch (Exception e) {
// handle exception...
} finally {
readLock.unlock();
}
return product;
}除了缓存空值,使用布隆过滤器也可以解决缓存穿透问题:
当布隆过滤器说某个key存在时,这个key可能不存在;当它说某个key不存在时,这个key肯定不存在。因此布隆过滤器可以用来过滤不存在的数据,能够有效阻止请求向后端传递。
布隆过滤器是一个大型的位数组+几种不同的无偏hash函数。由于存储结构使用的是位数组,布隆过滤器相比缓存空值占用的空间非常小,长度为1亿的位数组大小也就10M多。
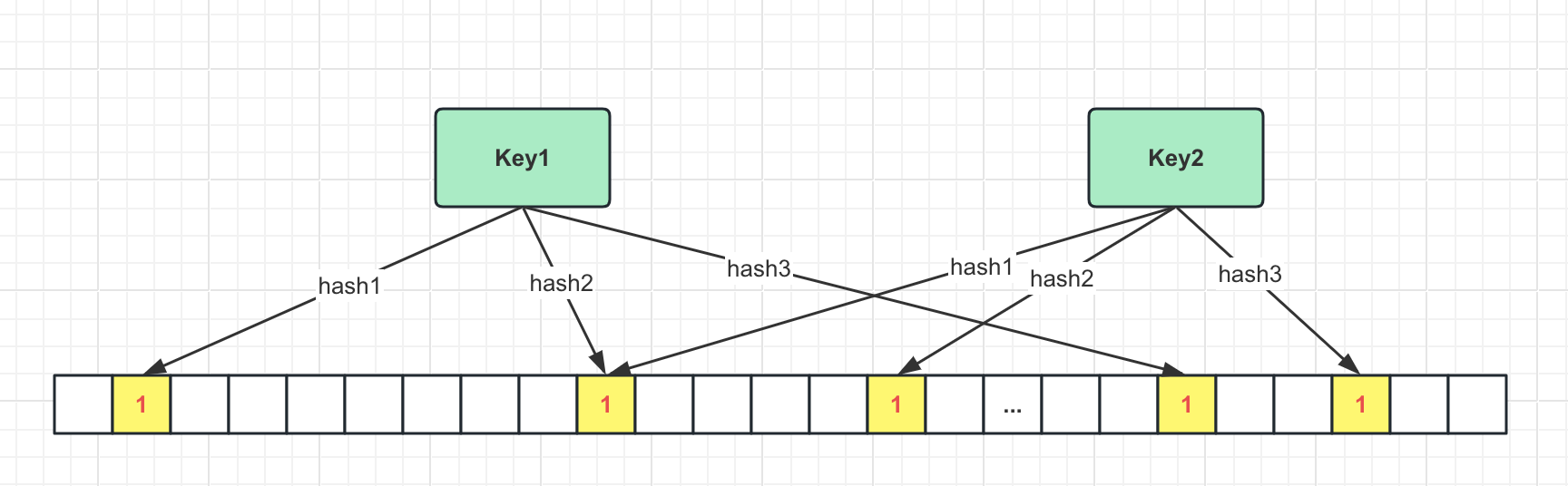
下面展示如何使用Redisson实现布隆过滤器:
public class ProductBloomFilter {
private final RedissonClient redissonClient;
private RBloomFilter<String> bloomFilter;
private final String BLOOM_FILTER_NAME = "bloom_filter:product"; // 会作为key存储到Redis
public ProductBloomFilter() {
// 初始化Redisson客户端
Config config = new Config();
config.useSingleServer().setPassword("luyee").setAddress("redis://111.231.11.199:8007");
this.redissonClient = Redisson.create(config);
// 初始化布隆过滤器
init();
}
/**
* 初始化布隆过滤器(由于布隆过滤器无法删除或修改数据,因此需要定期调用该方法)
*/
public void init() {
if (this.bloomFilter != null && this.bloomFilter.isExists()) {
this.bloomFilter.delete(); // 删除原布隆过滤器
}
this.bloomFilter = this.redissonClient.getBloomFilter(BLOOM_FILTER_NAME);
this.bloomFilter.tryInit(
100L, // expectedInsertions:预计元素个数
0.03 // falseProbability:误判率
);
}
/**
* 每次缓存时,也将key添加到布隆过滤器
*/
public void cacheProduct(String productKey) {
this.bloomFilter.add(productKey);
}
/**
* 使用布隆过滤器判断key是否存在
*/
public boolean productExists(String productKey) {
return this.bloomFilter.contains(productKey);
}
}布隆过滤器不能删除或修改数据,因此需要定期重新初始化布隆过滤器
缓存和数据库双写不一致问题
一般有更新数据库后有两种更新缓存的方式,即更新数据库后更新缓存和更新数据库后删除缓存,但是这两种方式都可能出现缓存数据库双写不一致的问题:
.png)
.png)
如果是写多读多的场景,就没必要使用缓存了,直接操作数据库就好。
如果并发很小或者可以容忍短暂的数据不一致,可以给缓存加上合理的过期时间或者使用阿里开源的canal来监听数据库binlog日志以及时修改缓存
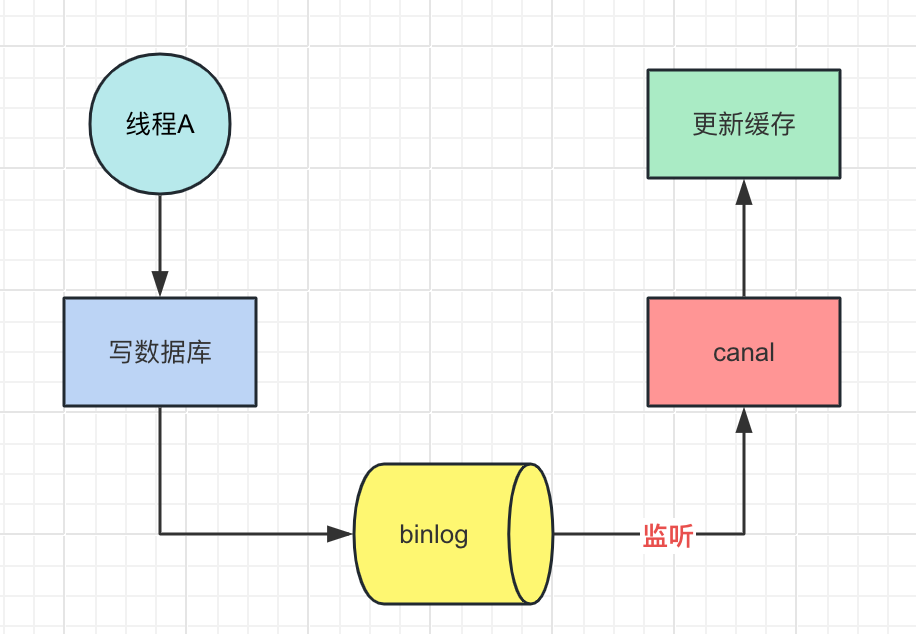
如果不能容忍数据不一致,可以通过加分布式锁解决这个问题(推荐使用读写锁,可保证并发读写和写写的时候串行执行,读读的时候相当于无锁)
下面举例使用读写锁解决双写不一致问题:
/**
* 创建商品
*/
public Product createProduct(Product product) {
Product productResult = null;
// 加锁(解决双写不一致问题)
RReadWriteLock productUpdateLock = redissonClient.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + product.getId()); // 使用读写锁优化
RLock writeLock = productUpdateLock.writeLock(); // 更新数据库操作,使用写锁
writeLock.lock();
try {
productResult = productDao.create(product);
stringRedisTemplate.opsForValue().set(PRODUCT_CACHE_PREFIX + product.getId(), JSON.toJSONString(productResult),
genProductCacheTimeout(), TimeUnit.SECONDS);
} catch (Exception e) {
// handle exception...
} finally {
writeLock.unlock();
}
return productResult;
}
/**
* 更新商品
*/
public Product updateProduct(Product product) {
Product productResult = null;
// 加锁(解决双写不一致问题)
RReadWriteLock productUpdateLock = redissonClient.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + product.getId()); // 使用读写锁优化
RLock writeLock = productUpdateLock.writeLock(); // 更新数据库操作,使用写锁
writeLock.lock();
try {
productResult = productDao.update(product);
stringRedisTemplate.delete(PRODUCT_CACHE_PREFIX + product.getId());
} catch (Exception e) {
// handle exception...
} finally {
writeLock.unlock();
}
return productResult;
}
private Product getProductFromDB(String id) {
Product product = null;
String cacheKey = PRODUCT_CACHE_PREFIX + id;
// 加锁(用于更新缓存时,解决双写不一致问题)
RReadWriteLock productUpdateLock = redissonClient.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + id); // 使用读写锁优化
RLock readLock = productUpdateLock.readLock(); // 查询数据库操作,使用读锁(允许多个线程并发执行:查询数据库+更新缓存)
readLock.lock();
try {
product = productDao.query(id);
if (product != null) {
stringRedisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
} else {
stringRedisTemplate.opsForValue().set(cacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);
}
} catch (Exception e) {
// handle exception...
} finally {
readLock.unlock();
}
return product;
}