Redis 核心数据结构
核心数据结构
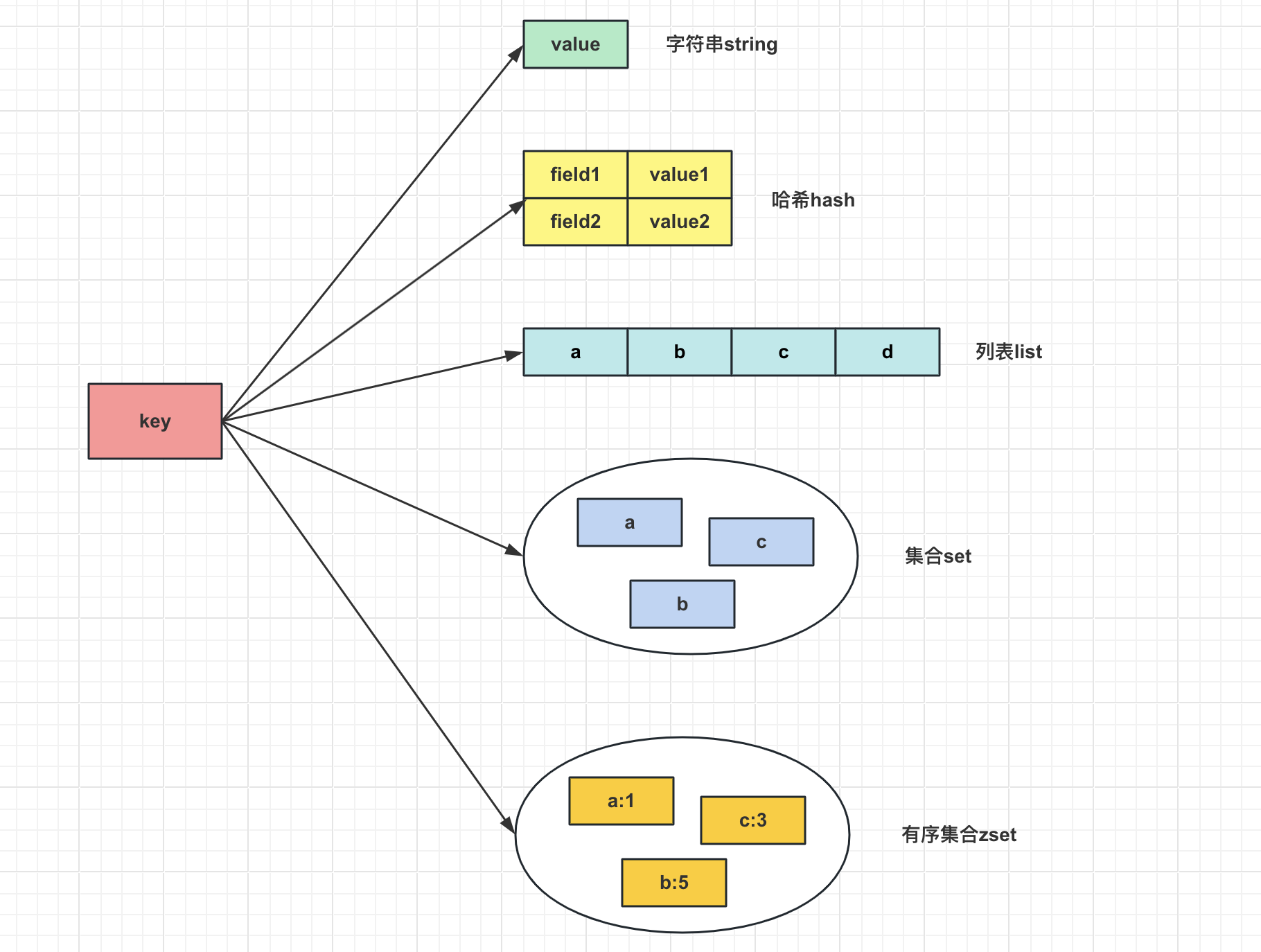
查询用法:如
help string
string 字符串
常用命令
# 基本操作
SET {key} {value} # 设置一个键值对
MSET {key1} {value1} {key2} {value2} {key3} {value3} … # 批量设置键值对
SETNX {key} {value} # 设置一个不存在的键值对(键不存在才能设置成功)
GET {key} {value} # 获取一个键值
MGET {key1} {key2} {key3} … # 批量获取键值
DEL {key} {value} # 删除一个键
EXPIRE {key} {seconds} # 设置一个键的过期时间
# 原子加减
INCR {key} # 将键中存储的数字值加1
DECR {key} # 将键中存储的数字值减1
INCRBY {key} {num} # 将键中存储的数字值加上num
DECRBY {key} {num} # 将键中存储的数字值减去num使用场景
(1) 单值缓存
以热更新状态为例:
SET hotupdate:enable true # 设置热更新开启
GET hotupdate:enable # 查询热更新状态(2) 对象缓存
以 user 为例:
# value是JSON字符串格式,适合很少修改的数据
SET user:1 {value(JSON字符串格式)}
# 将 value 分属性一一存储,适合经常修改的数据,可以方便修改部分属性
MSET user:1:name Tom user:1:balance 100
MGET user:1:name user:1:balance(3) 分布式锁
以操作id为1001的商品为例:
SET product:1001 true ex 10 nx # 返回1表示操作获取锁成功,返回0表示获取锁失败(需要设置超时时间,避免程序意外终止导致的死锁)
# 获取到锁的线程执行业务操作…
DEL product:1001 # 执行完业务操作释放锁(4) 计数器
以id为666的文章阅读量为例:
INCR article:readcount:666
GET article:readcount:666```
(5) Web集群Session共享
如:集群间 Spring Session 共享
(6) 分布式系统全局id
INCR orderId 1000 # 一次分配一个批id(如1000个)给一个客户端节点,该节点用光这一批id再来redis申请下一批,这样性能更高hash 哈希
hash相当于双重map结构
优点:
整合了同类数据,方便数据管理
相比string操作时更节省内存和cpu
相比string更节省存储空间
缺点:
不支持在filed上设置过期,只能在key上设置过期
Redis集群架构下不适合大规模使用
常用命令
HSET {key} {filed} {value} # 设置某个hash的一个filed->value对
HSETNX {key} {filed} {value} # 设置某个hash的一个不存在的filed->value对
HMSET {key} {filed1} {value1} {filed2} {value2} {filed3} {value3} … # 设置某个hash的多个filed->value对
HGET {key} {filed} # 获取某个hash的某个filed对应的值
HGET {key} {filed1} {filed2} {filed3} … # 获取某个hash的多个filed对应的值
HDEL {key} {filed} # 删除某个hash的某个filed->value对
HLEN {key} # 获取某个hash的所有filed数目
HGETALL {key} # 获取某个hash的所有filed->value对使用场景
(1) 对象缓存(注意bigkey问题,如果key对应的filed->value对太多,则操作该key的性能很低,需要进行分段处理)
HMSET user 1:name Tom 1:balance 100
HMSET user 1:name 1:balance(2) 购物车(最终购物车数据还是要入库)
以用户id为key,商品id为field,商品数量为value:
HSET cart:1 1001 1 # id为1的用户添加1个id为1001的商品到购物车
HINCRBY cart:1 1001 1 # id为1的用户将购物车中id为1001的商品的数量加1
HLEN cart:1 # 查询id为1的用户的购物车商品数目
HDEL cart:1 1001 # 将id为1的用户的购物车中id为1001的商品删除
HGETALL cart:1 # 获取id为1的用户的购物车中的所有商品list 列表
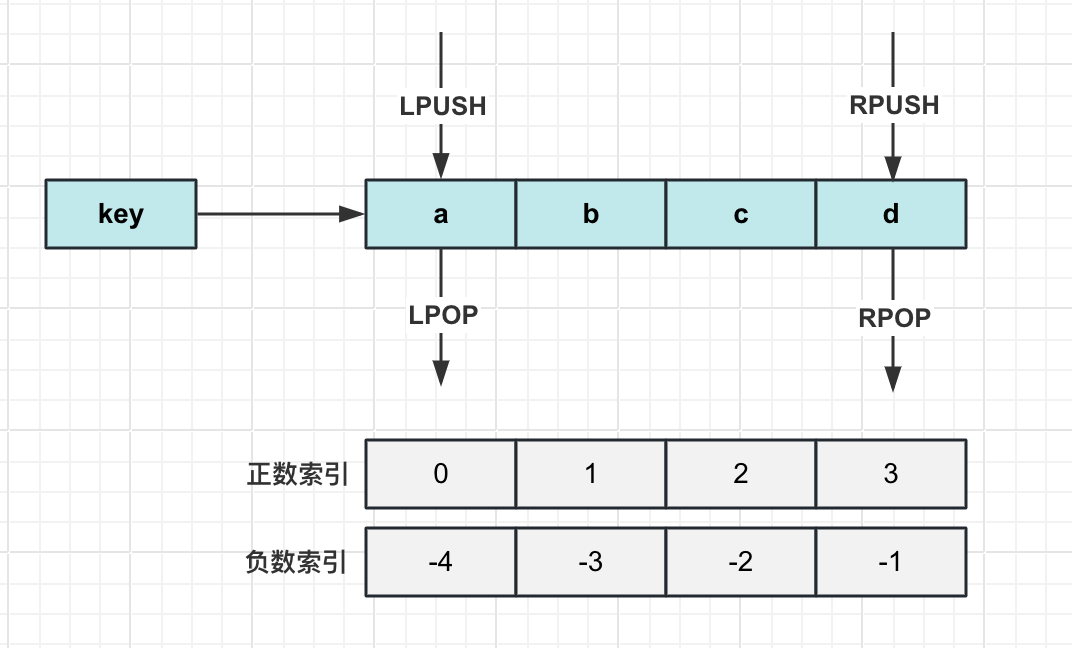
常用命令
LPUSH {key} {value1} {value2} {value3} … # 将一个或多个value值插入到列表key的头部(最左边)
RPUSH {key} {value1} {value2} {value3} … # 将一个或多个value值插入到列表key的尾部(最右边)
LPOP {key} # 移除并返回列表key的头元素
RPOP {key} # 移除并返回列表key的尾元素
BLPOP {key} {timeout} # 移除并返回列表key的头元素,如列表中没有元素,阻塞等待timeout秒(timeout为0时会一直阻塞等待)
BRPOP {key} { {timeout}} # 移除并返回列表key的尾元素,如列表中没有元素,阻塞等待timeout秒(timeout为0时会一直阻塞等待)
LRANGE {key} {start} {stop} # 返回列表key指定区间内的元素,start和stop分别表示区间起始偏移量list实现分布式数据结构
栈(Stack):LPUSH + LPOP
队列(Queue):LPUSH + RPOP
阻塞队列(Blocking Queue):LPUSH + BRPOP
使用场景:按时间排序的消息流
以微信公众号为例,假设id为1的用户关注了微信公众号A、B、C,id为2的用户关注了微信公众号A、C:
# 1.公众号A发布文章,文章id为1001
LPUSH subscription:1 1001
LPUSH subscription:2 1001
# 2.公众号B发布文章,文章id为1234
LPUSH subscription:1 1234
# 3.公众号C发布文章,文章id为2333
LPUSH subscription:1 2333
LPUSH subscription:2 2333
# 4.id为1的用户查看微信订阅中最新的10篇文章
LRANGE subscription:1 0 9
# 5.id为2的用户查看微信订阅中最新的10篇文章
LRANGE subscription:2 0 9如果公众号有很多订阅用户,需要做相应的优化,如一开始只给在线的用户发,其他用户在后台慢慢发;如使用PULL模式,或PUSH和PULL相结合
set 集合
常用命令
# 基本操作
SADD {key} {member1} {member2} {member3} … # 往集合key中添加元素,元素存在则忽略,key不存在则创建
SREM {key}{member1} {member2} {member3} … # 从集合key中移除元素
SMEMBERS {key} # 获取集合key中的所有元素
SCARD {key} # 获取集合key中的元素个数
SISMEMBER {key} {member} # 判断元素member是否存在于集合key中
SRANDMEMBER {key} {count} # 随机从集合key中选出count个元素,不删除选出的元素
SPOP {key} {count} # 随机从集合key中选出count个元素,并删除选出的元素
# 集合操作
SINTER {key1} {key2} {key3} … # 交集运算
SINTERSTORE {destination} {key1} {key2} {key3} … # 将交集运算的结果放入新集合destination中
SUNION {key1} {key2} {key3} … # 并集运算
SUNIONSTORE {destination} {key1} {key2} {key3} … # 将并集运算的结果放入新集合destination中
SDIFF {key1} {key2} {key3} … # 差集运算(在集合key1中,不在集合key2,key3…中)
SDIFFSTORE {destination} {key1} {key2} {key3} … # 将差集运算的结果放入新集合destination中使用场景
(1) 抽奖
# id为1的用户参与id为18183的抽奖活动
SADD choujiang:18183 1
# 查看参与抽奖的所有用户
SMEMBERS choujiang:18183
# 开奖方式1:抽2个人中奖
SRANDMEMBER choujiang:18183 2
# 开奖方式2:5个三等奖,3个二等奖,1个一等奖
SPOP choujiang:18183 5
SPOP choujiang:18183 3
SPOP choujiang:18183 1(2) 点赞 & 收藏
# 点赞
SADD like:{文章id} {用户id}
# 取消点赞
SREM like:{文章id} {用户id}
# 查询用户是否点赞
SISMEMBER like:{文章id} {用户id}
# 查询所有点赞的用户
SMEMBERS like:{文章id}
# 查询点赞数
SCARD like:{文章id}(3) 关注模型(通过集合操作实现)
# Tom关注的人
SMEMBERS followee:Tom -> {Jerry, Spike, Topsy}
# Jerry关注的人
SMEMBERS followee:Jerry -> {Tom, Spike, Tuffy}
# Tom和Jerry共同关注
SINTER followee:Tom followee:Jerry -> {Spike}
# Tom可能认识的人
SDIFF followee:Jerry followee:Tom -> {Tuffy}(4) 多级筛选(通过差集运算实现)
SINTER os:Android cpu:HiSilicon ram:16G -> {P40}zset 有序集合
常用命令
# 基本操作
ZADD {key} {score1} {member1} {score2} {member2} {score3} {member3} … # 往有序集合key中添加带分值的元素
ZREM {key} {member1} {member2} {member3} … # 从有序集合key中删除元素
ZSCORE {key} {member} # 查询有序集合key中元素member的分值
ZINCRBY {key} {increment} {member} # 将有序集合key中元素member的分值增加increment
ZCARD {key} # 查询有序集合key的元素个数
ZRANGE {key} {start} {stop} [WITHSCORES] # 按照分值从低到高的顺序,获取有序集合key中指定区间的元素
ZREVRANGE {key} {start} {stop} [WITHSCORES] # 按照分值从高到低的顺序,获取有序集合key中指定区间的元素
# 集合操作
ZINTERSTORE {destkey} {numkeys} {key1} {key2} {key3} … # 交集运算
ZUNIONSTORE {destkey} {numkeys} {key1} {key2} {key3} … # 并集运算使用场景:排行榜
以每日热点新闻为例:
# 点击新闻
ZINCRBY hotNews:20240523 1 {}
# 展示当天的10条热点新闻
ZREVRANGE hotNews:20240523 0 9 WITHSCORES
# 计算一周的10条热点新闻
ZUNIONSTORE hotNews:20240517-20240523 7 hotNews:20240517 hotNews:20240518 … hotNews:20240523
# 展示一周的10条热点新闻
ZREVRANGE hotNews:20240517-20240523 0 9 WITHSCORES
License:
CC BY 4.0