Redis 集群架构
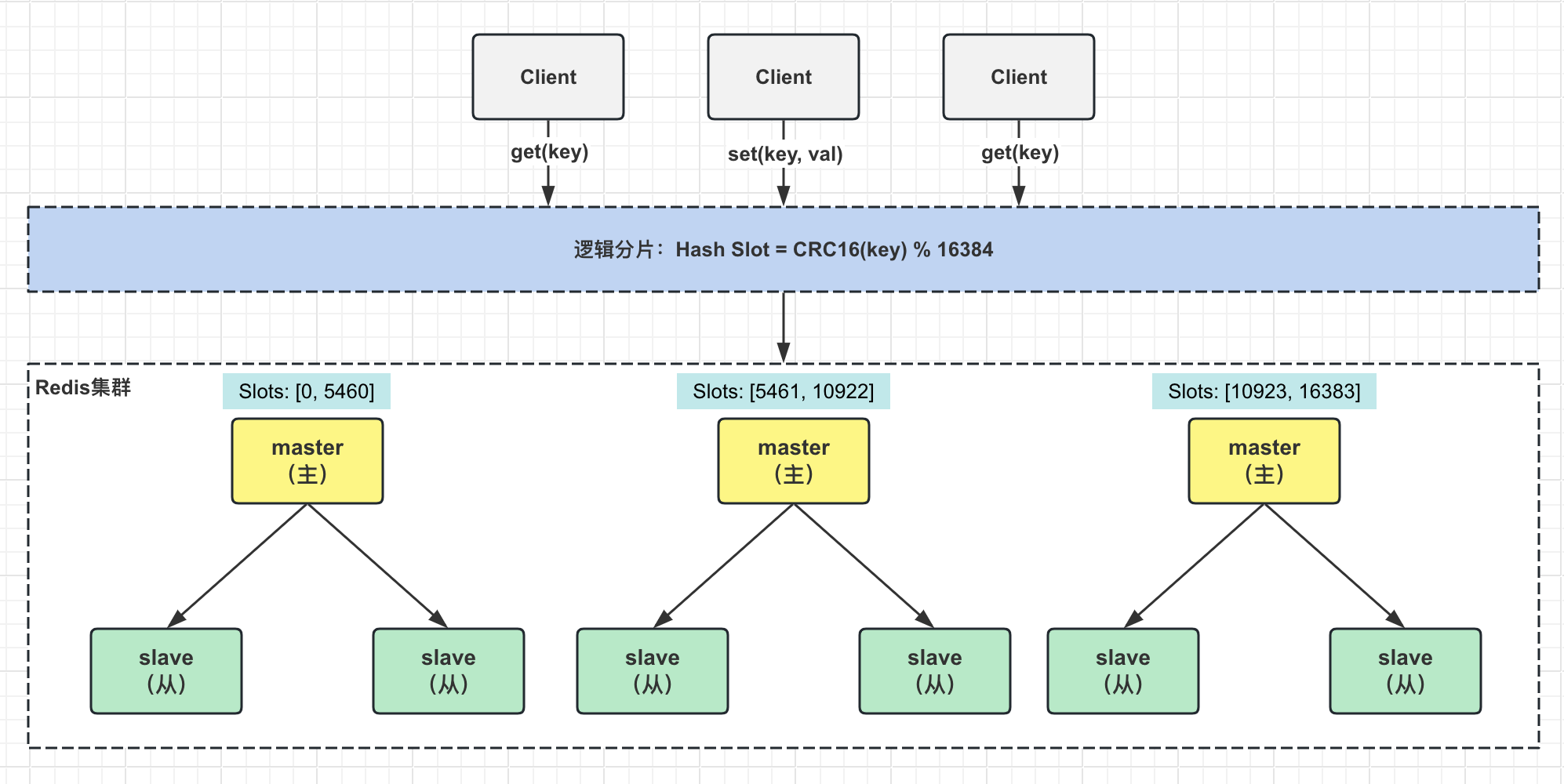
Redis集群架构包含了哨兵和主从复制的能力,其中的每个小集群类似哨兵架构,主节点失效了也会重新选新的主节点。
不同的是:
集群架构中的数据是分片存储在不同节点的,而不是像哨兵架构所有数据存存储在一个节点
哨兵架构主从切换时存在访问瞬断问题,集群架构只有主从切换的那个小集群存在访问瞬断问题,其他小集群可以正常提供服务
哨兵架构只有一个主节点提供服务,无法支持较高的并发,而集群架构可以将请求hash分散到每个小集群,能够支持高并发
哨兵架构内存也能设置太大,否则会导致持久化文件过大,而集群架构的可以横向扩容小集群,能够支持大业务量(最多能支持上万个,官方推荐不要超过1000个)
Redis集群所有从节点不提供读写服务,默认情况下任意小集群失效整个集群不能提供服务
Redis集群搭建
Redis集群要求至少3个主节点,下面用3台服务器来搭建3个小集群,每个小集群1主2从,一共9个Redis实例:
# 1. 给每个实例创建一个数据存放目录
mkdir -p /usr/local/redis-cluster/<port>
# 2. 复制redis.conf到数据存放目录(<port>替换成Redis实例端口)
cp redis.conf /usr/local/redis-cluster/<port>
# 3. 修改复制的配置文件
sed -i "s/daemonize no/daemonize yes/" redis.conf
sed -i "s/port 6379/port <port>/" redis.conf
sed -i "s@dir ./@dir /usr/local/redis-cluster/<port>/@" redis.conf
sed -i "s@pidfile /var/run/redis_6379.pid@pidfile /var/run/redis_<port>.pid@" redis.conf
sed -i "s/bind 127.0.0.1 -::1/#bind 127.0.0.1 -::1/" redis.conf
sed -i "s/protected-mode yes/protected-mode no/" redis.conf
sed -i "s/appendonly no/appendonly yes/" redis.conf # 开启AOF
sed -i "s/# cluster-enabled yes/cluster-enabled yes/" redis.conf # 开启集群模式
sed -i "s/# cluster-config-file nodes-6379.conf/cluster-config-file nodes-<port>.conf/" redis.conf # 集群节点信息存储文件
sed -i "s/# cluster-node-timeout 15000/cluster-node-timeout 5000/" redis.conf
sed -i "s/# requirepass foobared/requirepass <password>/" redis.conf # 设置Redis访问密码(<password>替换成实际密码)
sed -i "s/# masterauth <master-password>/masterauth <password>/" redis.conf # 设置集群节点间访问密码(同上)
# 4. 逐一启动Redis实例
./redis-server /usr/local/redis-cluster/<port>/redis.conf
# 5. 创建Redis集群
# 防火墙需要开放Redis服务端口(默认6379)和集群节点gossip通信端口(默认16379=6379+10000)
# 为了提高集群的可用性,主从节点会被尽量分散在不同的机器上
./redis-cli -a <password> --cluster create --cluster-replicas <replica_num> <host1:port1> <host2:port2> <host3:port3>… # replica_num
表示一个小集群的从节点数,最前面的几个<host:port>是主节点
# 6. 验证集群是否创建成功
./redis-cli -a <password> -c -h <host> -p <port> # -c表示集群模式
cluster info # 查看集群信息
cluster nodes # 查看集群节点信息
set <key> <value> # 验证数据操作
# 如何关闭集群
./redis-cli -a <password> -c -h <host> -p <port> shutdown
# 如何重启集群
./redis-server /usr/local/redis-cluster/<port>/redis.conf下面记录了一些关键步骤:
检查Redis实例是否都启动:



创建Redis实例:
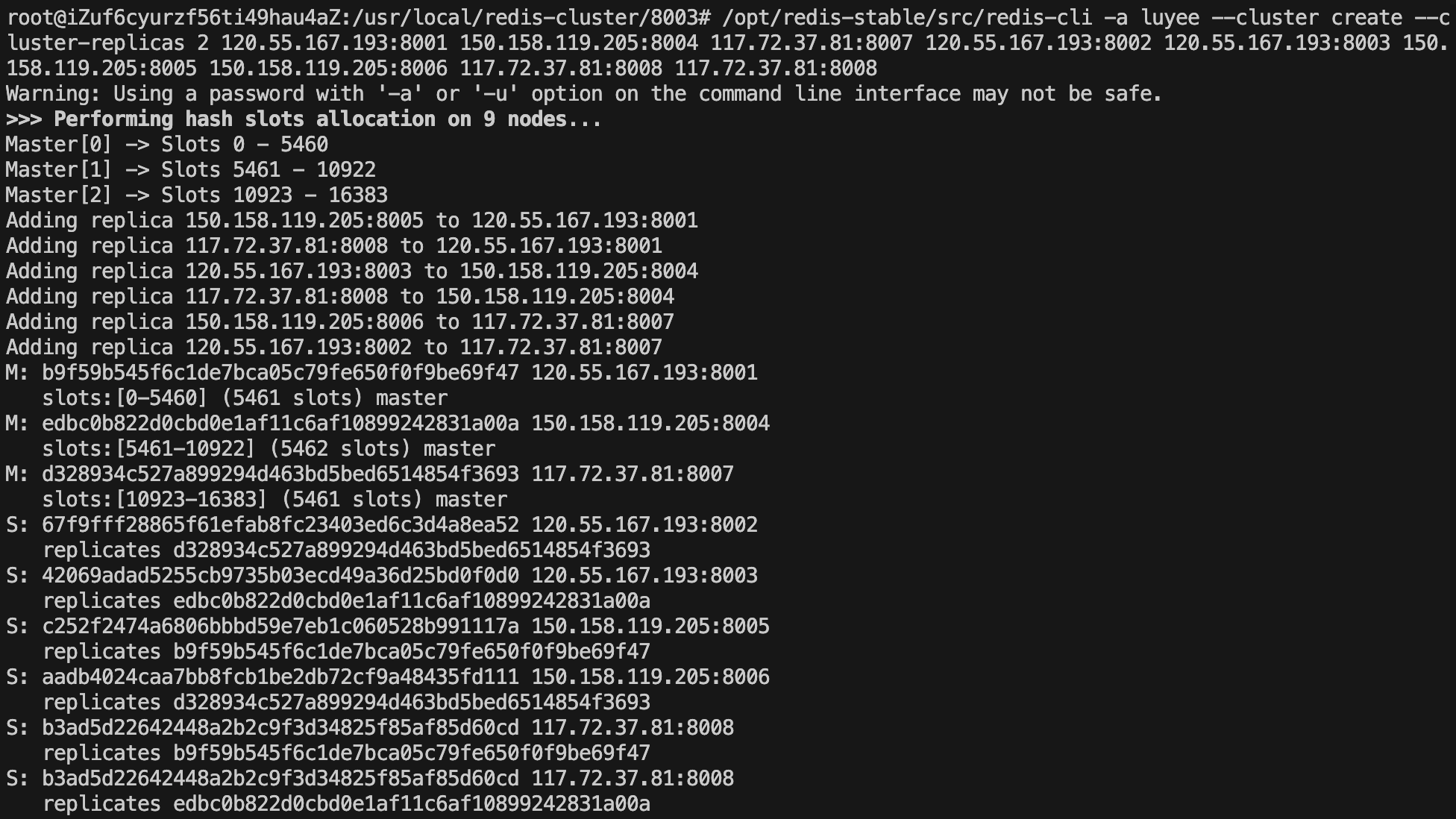
查看Redis集群信息:

Jedis访问Redis集群
(1) 普通代码方式访问
GenericObjectPoolConfig jedisPoolConfig = new JedisPoolConfig();
// jedis 连接池配置
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMinIdle(5);
// 集群所有节点
Set<HostAndPort> clusterNodes = new HashSet<>();
clusterNodes.add(new HostAndPort("120.55.167.193", 8001));
clusterNodes.add(new HostAndPort("120.55.167.193", 8002));
clusterNodes.add(new HostAndPort("120.55.167.193", 8003));
clusterNodes.add(new HostAndPort("150.158.119.205", 8004));
clusterNodes.add(new HostAndPort("150.158.119.205", 8005));
clusterNodes.add(new HostAndPort("150.158.119.205", 8006));
clusterNodes.add(new HostAndPort("117.72.37.81", 8007));
clusterNodes.add(new HostAndPort("117.72.37.81", 8008));
clusterNodes.add(new HostAndPort("117.72.37.81", 8009));
// 连接集群
// connectionTimeout: 6000 表示客户端连接超时时间
// soTimeout: 5000 表示客户端读写超时时间
// xxx: 表示Redis密码
try (JedisCluster jedisCluster = new JedisCluster(clusterNodes, 6000, 5000, 10, "xxx", jedisPoolConfig)) {
// 读写操作
System.out.println(jedisCluster.set("cluster", "520"));
System.out.println(jedisCluster.get("cluster"));
} catch (Exception e) {
System.out.println(e.getMessage());
}(2) Spring Boot方式访问
application.yaml配置:
spring:
redis:
database: 0 # Redis数据库编号,默认有16个数据库,编号从0到15
timeout: 5000
password: xxx
cluster:
nodes: 120.55.167.193:8001,120.55.167.193:8002,120.55.167.193:8003,150.158.119.205:8004,150.158.119.205:8005,150.158.119.205:8006,117.72.37.81:8007,117.72.37.81:8008,117.72.37.81:8009
lettuce:
pool:
max-idle: 10
min-idle: 5
max-active: 20
max-wait: 1000访问代码:
public void testCluster() {
for (int i = 1; i <= 3; i++) {
try {
// 会使用 key 的 {test_cluster} 前缀来 hash,使得这批 key 可以存入同一个 slot
// RedisTemplate是SpringDataRedis中对Jedis API的高度封装
stringRedisTemplate.opsForValue().set("{test_cluster}:" + i, String.valueOf(i));
System.out.println("设置key:{test_cluster}:" + i);
Thread.sleep(6000);
} catch (Exception e) {
System.out.println("设置key出错:{test_cluster}:" + i);
}
}
}集群原理
Redis Cluster将所有数据划分为16384个Slot,每个节点负责其中一部分Slot,每个节点都记录了集群的Slot分配信息(默认记录在nodes-<port>.conf中)。
客户端首次连接上集群后,会缓存从节点获取到的集群Slot分配信息,因此客户端后续发送读写请求的时候,能够通过key计算出的Slot找到对应的节点去发送。
key的Slot定位算法
读写操作前,通过key计算Slot:
public class ClusterCommandArguments extends CommandArguments {
// …
protected CommandArguments processKey(String key) {
int hashSlot = JedisClusterCRC16.getSlot(key); //
if (this.commandHashSlot < 0) {
this.commandHashSlot = hashSlot;
} else if (this.commandHashSlot != hashSlot) {
throw new JedisClusterOperationException("Keys must belong to same hashslot.");
}
return this;
}
}
// 具体的Slot定位算法:对key用CRC16哈希算法计算出一个hash值,将这个hash值对16384进行取模
public final class JedisClusterCRC16 {
// …
public static int getSlot(String key) {
if (key == null) {
throw new NullPointerException("Slot calculation of null is impossible");
} else {
key = JedisClusterHashTag.getHashTag(key);
return getCRC16(key) & 16383; // getCRC16(key) & 16383 等价于 getCRC16(key) % 16384
}
}
}请求重定位
当客户端向一个错误的节点发送读写请求(错误节点指的是读写请求的key对应的Slot不归该节点负责),该节点会向客户端发送一个携带正确节点的跳转指令,告诉客户端去这个节点上执行读写操作,同时会更新客户端本地的节点Slot映射表缓存。

Redis集群节点间的通信机制
集群往往需要维护一定的元数据,如节点IP端口、节点存活状态、主从信息、Slot分配信息等,一般有分散式和集中式两种方式维护集群元数据。
Redis集群使用的是分散式机制,它将元数据存储在所有节点上,不同节点之间进行不断的Gossip通信来维护元数据的最终一致性。
Gossip协议的依据是六度分隔理论,即一个人通过6个中间人可以认识世界任何人,因此也叫流行病协议,它以类似流行病传播的方式在节点间分享信息。
通常Gossip协议的实现方式:以给定的频率,每个节点随机选择N个节点发送消息。
Redis集群常见Gossip消息类型
(1) meet:集群中已有节点会向新节点发送meet消息,邀请新节点加入集群,然后新节点就会开始和其他节点进行通信
(2) ping:每个节点都会按照配置的时间间隔向集群中其他节点发送ping消息,消息中包含自己的状态和维护的集群元数据信息
(3) pong:对meet和ping消息的响应
(4) fail:一个节点判断某个节点fail后,就会发送fail消息给其他节点,其他节点收到消息标记该节点为fail状态
Gossip通信的端口
每个Redis节点都有一个专门用于节点间Gossip通信的端口,它的值是自己的服务端口号+10000,比如Redis服务端口是6379,则Gossip端口为16379。
网络抖动
机房网络抖动是非常常见的现象,突然之间部分连接会变得不可用,然后很快又恢复正常。
Redis集群中某个节点出现网络抖动时,容易被错误地判定为节点故障,导致频繁的主从切换,其间会发生大量的数据重新复制。
为此,Redis引入cluster-node-timeout参数,只有当某个节点持续cluster-node-timeout的时间失联时,才可以认定该节点故障,需要进行主从切换。
cluster-node-timeout值应设置得稍大一些,如果值太小,小集群中可能出现多个master节点,导致脑裂问题
Redis小集群选举原理
(1) slave发现自己的master变为fail状态
(2) 将自己记录的currentEpoch值加1,并广播FAILOVER_AUTH_REQUEST消息(FAILOVER:故障转移)
currentEpoch可以当作集群状态变更的版本号,当前只用于slave发起的故障转移流程,每个节点都会记录currentEpoch值,当节点收到的其他节点发来的currentEpoch大于自己的currentEpoch,就会更新currentEpoch为发送者的currentEpoch。
(3) 其他节点收到该消息,只有master节点会响应,判断请求合法后,发送FAILOVER_AUTH_ACK消息(对于同一个Epoch值只会发送一次ACK)
(4) 发起failover的slave收集各个master返回的FAILOVER_AUTH_ACK消息
(5) 收到超过半数master的FAILOVER_AUTH_ACK消息的slave变成新的master
举例:如果有3个master节点,那么半数为1.5,则超过半数表示至少2个节点
这就是Redis集群至少需要3个master节点的原因:如果只有2个master节点,某个master故障后,任意slave都无法获得超过半数master同意
(6) slave广播pong消息通知其他节点
如果master发生故障的小集群中,没有slave收到的ACK超过半数,则各自将自己的currentEpoch+1后重新选举。
并且为了减少选举轮次,slave发现master故障后,并不是立即发起选举,为了尽量让slave错峰选举,发起选举有一个随机的延迟时间:
DELAY = 500ms + random(0, 500)ms + SLAVE_RANK * 1000ms
SLAVE_RANK表示slave已经从master复制的数据总量得分,RANK越小表示复制的数据越新,理论上持有最新数据的slave会先发起选举
解决集群脑裂导致数据丢失问题
Redis没有半数写入机制,一个master节点和其他节点发生网络分区时,会选出一个新的master节点,此时客户端继续发起数据写入请求,一旦网络分区恢复,会将其中一个master节点变为slave节点,将导致大量数据丢失(全量主从复制时slave会清空自己的数据)。
为了解决这个问题,可以在Redis配置中加上下面的参数:
# min-replicas-to-write表示写数据至少同步多少slave才算成功,可以使用该参数模仿ZooKeeper的半数写入机制,即超过半数节点写入才算成功,这样即使发生脑裂,也只会有一个master可以写入数据,解决了脑裂导致的数据丢失问题(并非100%不丢失数据)
min-replicas-to-write 1 # 如果小集群有3个节点,半数写入机制要求至少2个节点写入,master本身算1个,则还需要1个slave写入成功,所以这里配置为1配置该参数会牺牲一定的可用性,Redis作为缓存大多数情况下允许丢失数据,因此一般不开启该参数
是否集群完整才能对外提供服务
Redis集群默认需要所有Slot都有非故障的master节点负责,才能对外提供服务。
通过配置`cluster-require-full-coverage no`,即时Redis集群不完整,也可对外提供服务。
为什么推荐master节点数为奇数
推荐master节点数为奇数是为了节省机器资源,例如4个master节点和3个master节点都最多只能有1个master节点出现故障,如果有2个master节点同时出现故障,4个master节点的集群也无法选举,因为选举超过半数规则需要至少3个master节点同意。
集群如何支持批量操作命令
对于mset、mget等批量操作命令,Redis集群不支持key落在不同节点的操作:

为了解决这个问题,Redis支持在一批key前面加上相同的{xxx}前缀,这样只会使用大括号中的内容计算hash值,可以确保这一批相同前缀的key落入同一个Slot:

这里只会使用大括号中的user:1的hash值计算Slot
集群运维
新增一个主节点
# 先启动要增加的节点
./redis-server /<path>/redis.config
# 执行节点新增命令(新增的节点默认是master节点)
./redis-cli -a <password> --cluster add-node <new_node_ip>:<new_node_port> <any_master_ip>:<related_port>
# 新增的主节点没有任何数据,因为没有分配Slot,也不能接受任何写入请求,因此需要执行下面的命令重新分片
./redis-cli -a <password> --cluster reshard <any_exist_node_ip>:<any_exist_node_port>
节点新增命令交互:
# 1 需要迁移Slot数
How many slots do you want to move (from 1 to 16384)?
# 2 把这些Slot迁移到哪个节点(用节点ID标识)
What is the receiving node ID?
# 3 从哪些节点迁移Slot(all表示所有节点)
Please enter all the source node IDs.
Type ‘all’ to use all the nodes as source nodes for the hash slots.
Type ‘done’ once you entered all the source nodes IDs.
# 4 输入yes确认迁移
Do you want to proceed with the proposed reshard plan (yes/no)?新增一个从节点
# 先启动要增加的节点
./redis-server /<path>/redis.config
# 客户端连接刚刚启动的节点
./redis-cli -a <password> -c -h <new_node_ip> -p <new_node_port>
# 将当前节点变成某个主节点的从节点
cluster replicate <master_node_id>删除一个从节点
./redis-cli -a <password> --cluster del-node <node_ip>:<node_port> <node_id>删除一个主节点
先把要删除的主节点已分配的Slot迁移到其他主节点中去,再执行节点删除操作。