MySQL 索引的底层数据结构
索引是用来高效获取数据的排好序的数据结构。
假设我们有一张user表,要在age字段上建索引:
实现索引需要排好序的数据结构,我们首先想到的是二叉搜索树(Binary Search Tree):

二叉搜索树的左右子树所有节点都小于根节点的值,并且所有子树也是二叉搜索树。用二叉搜索树做索引主要有两个问题:
一个问题是数据量大了后树高会很高,由于每查询一个节点就要进行一次磁盘IO,效率会非常低下。
另一个问题是对于大致有序的数据会形成一条长链,导致索引基本失去作用。
假如user表中的age数据是有序的:
索引就会变成这样的一条长链:
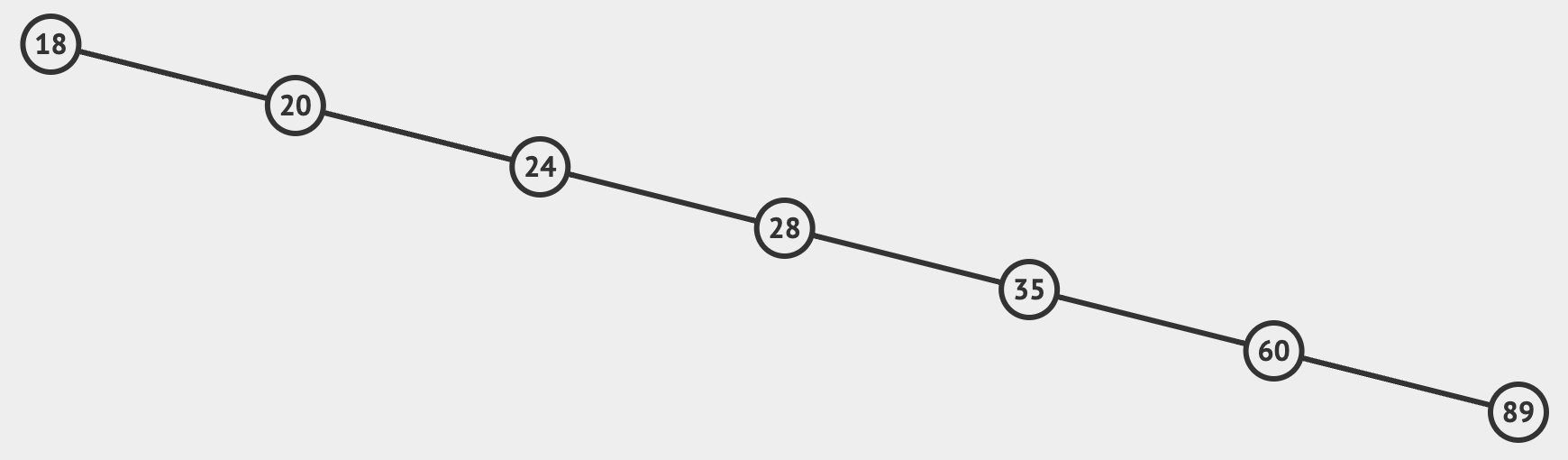
如果要获取age=89的数据,需要整整7次磁盘IO,相当于索引完全失效了,因此MySQL索引即没有考虑普通的二叉搜索树。
到这里,你可能会想到红黑树:
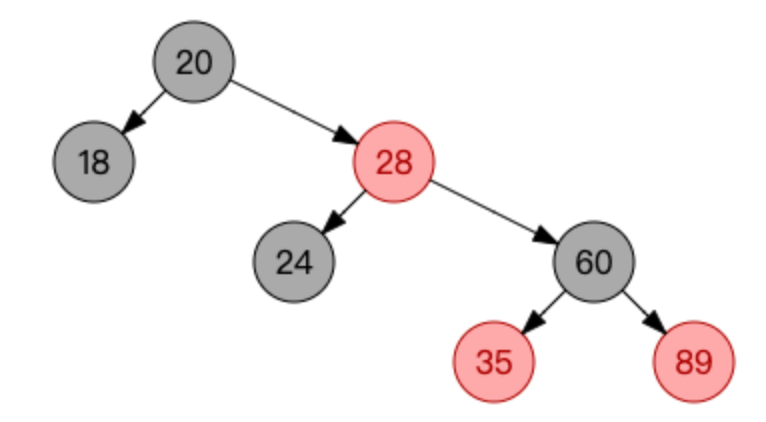
红黑树是一种自平衡的二叉搜索树,它确实可以解决长链问题,但是无法解决树高问题,因此MySQL索引也没有考虑红黑树。
树高问题的根源在于每个节点只存储了一条数据,那么有没有一种数据结构可以每个节点存储多条数据呢?有的,这种数据结构就是B树。
B树有如下特征:
每个节点可以存放多个元素,节点内和节点间的元素都是从左到右递增排列
每个节点都存储索引和数据
非叶子节点的子树数量大于两个且不能有空树
叶子结点具有相同的深度
所有索引元素不重复,即不会冗余存储
描述一颗B树时需要说明它的阶数(order),阶数表示一个节点最多可以有多少个子树
由于user表数据有点少,难以看出B树的特点,下面给user表增加3行数据:
下面是age字段的4阶的B树:
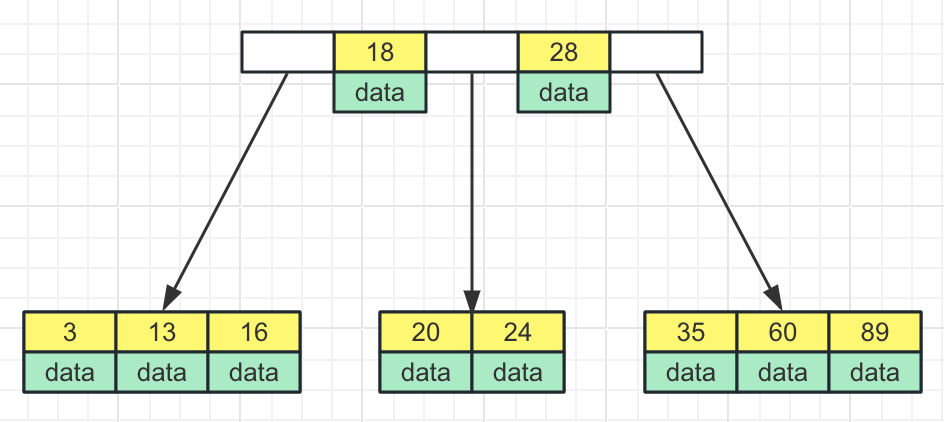
由于每个节点能够存放多条数据,因此B树的树高不会太高,基本满足了做索引的要求。但是MySQL却没有使用B树做索引,而是用了B+树。
B+树相当于B树的变种,不同于B树的是:
非叶子结点不存储数据,只存储索引,叶子结点才存储索引和数据
叶子节点之间通过双向链表连接,提高了区间访问性能
非叶子结点会冗余存储部分索引元素
下面是age字段的4阶B+树:
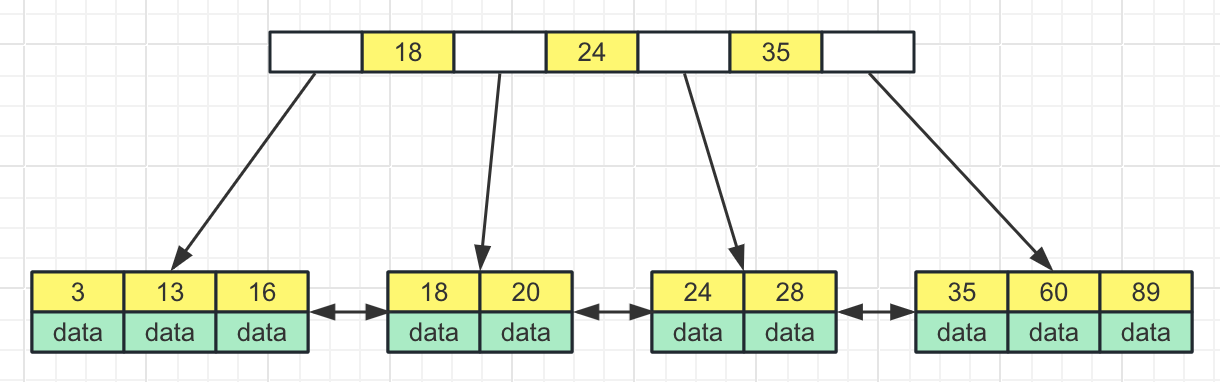
在B+树索引中查找元素的过程,以查找age=28为例:
将根节点数据从磁盘加载到内存中
使用二分查找算法确定元素在24和35之间
将24和35之间指向的节点数据从磁盘加载到内存中
使用二分查找算法找到元素28的数据
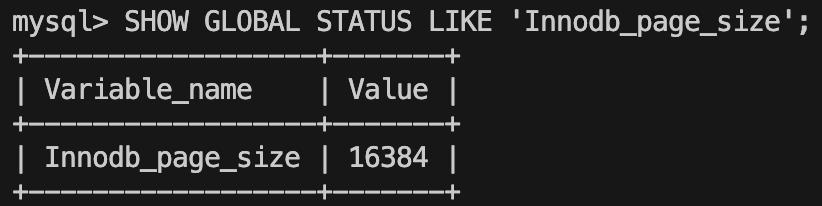
在InnoDB中,B+树索引的每个节点都是一个页,默认大小为16KB,可以通过 SHOW GLOBAL STATUS LIKE 'Innodb_page_size;' 查询页大小:
假设age字段类型为bigint,占8个字节,MySQL中指针占6个字节,对于非叶子节点,粗略估算一个页可以存放16384/(6+8)≈1170条索引。
一般一条数据大小不会超过1KB,如果树高为3,最大约可以存放1170*1170*16=21902400条数据(2000W+),对于大多数表都够用了。
而且根据版本不同,MySQL会把根节点或者所有非叶子节点常驻内存,这样的话,仅仅只需要一两次磁盘IO就可以把数据查出来,效率非常高。
如果使用B树,非叶子节点也存储数据,B树要存储2000W数据的话,树高至少为6,这就是MySQL选择B+树的原因。
此外,MySQL不仅支持用BTREE数据结构实现索引,还可用HASH数据结构实现索引,即对索引的key进行hash运算后取模计算索引存储的位置:
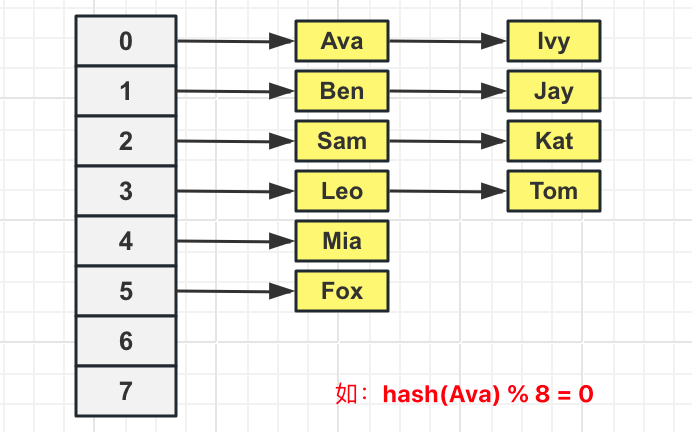
很多时候HASH索引要比B+树要更高效,但是绝大多数情况下,我们会用BTREE索引,这是因为HASH索引不支持范围查询,仅支持`=`和`in`查询。
### MyISAM和InnoDB索引和数据存储文件
在ubuntu系统中,MySQL5.7的数据存储目录是`/var/lib/mysql`,这个目录下的文件夹是一个个数据库,如`test`数据库:
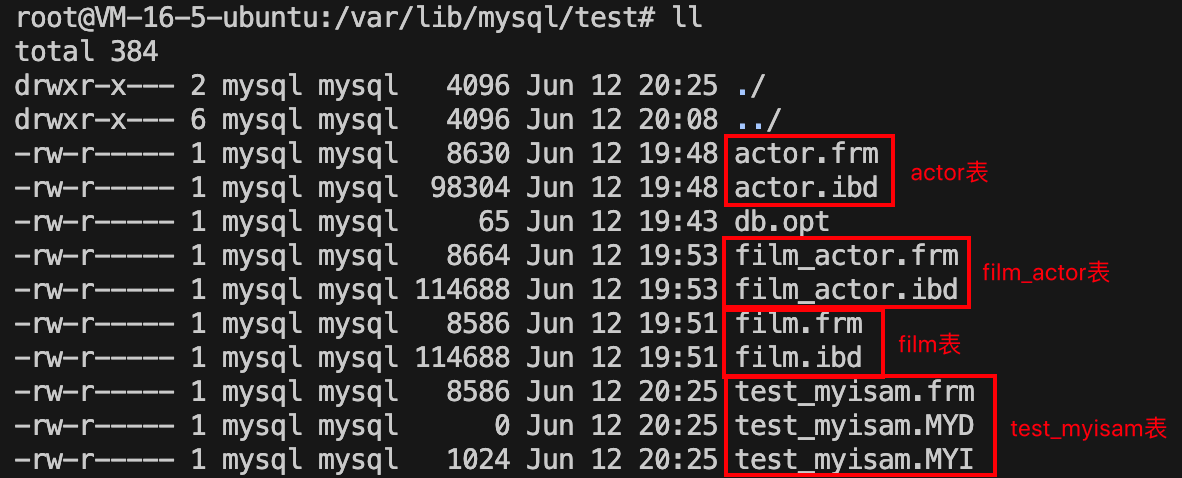
在`test`目录下,是这个数据库中的表数据文件:
如果表的存储引擎是MyISAM:
*.frm文件存储表结构信息(frm:Form)*.MYI文件存储索引(MYI:MyISAM Index)*.MYD文件存储数据(MYD:MyISAM Data)
MyISAM表的索引和数据分开存储在不同文件中
如果表的存储引擎是InnoDB:
*.frm文件存储表结构信息*.ibd文件存储索引和数据(ibd:InnoDB Data)
InnoDB表的索引和数据存储在同一个文件中
在MyISAM表中查找数据的过程:
通过MYI文件中的索引,获取对应的数据地址
根据拿到的数据地址,在MYD文件中定位数据
聚集索引和非聚集索引
聚集索引的叶子节点包含完整的数据记录,非聚集索引xxx
InnoDB主键索引是聚集索引(聚簇索引):
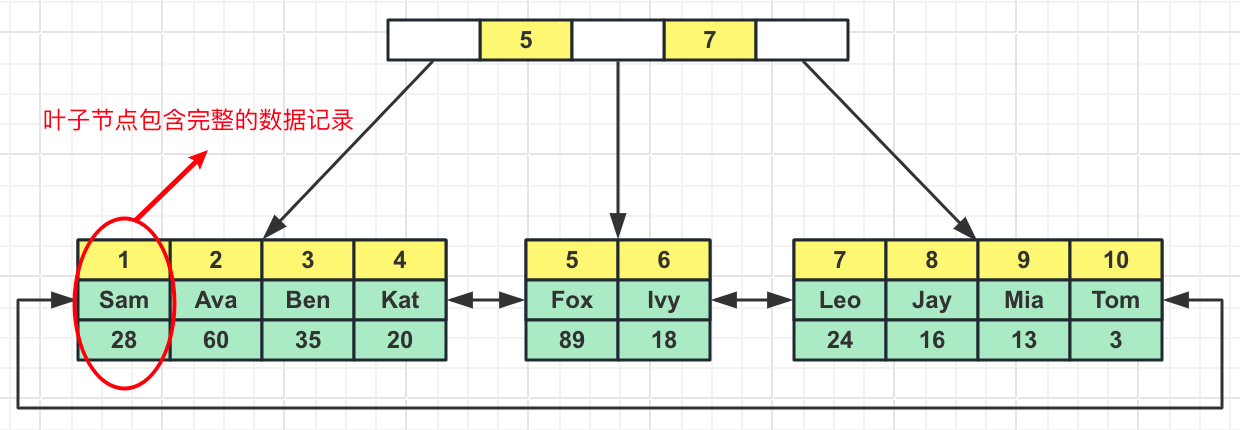
InnoDB非主键索引都是非聚集索引(在MySQL中也叫二级索引):
使用非聚集索引查询数据时,需要执行回表操作,即在非聚集索引找到需要的主键/非NULL唯一索引/row_id后返回聚集索引查询完整的数据记录。
因此使用非聚集索引查询数据要比使用聚集索引查询数据慢,既如此,为什么不全都使用聚集索引呢?这主要是为了节省存储空间,如果所有索引都存储完整的行记录,一张表需要的存储空间将增大为当前的好几倍;另外,也有一致性的原因,如果每个索引都保存完整的行数据,修改数据时需要保证每个索引的数据都更新成功。
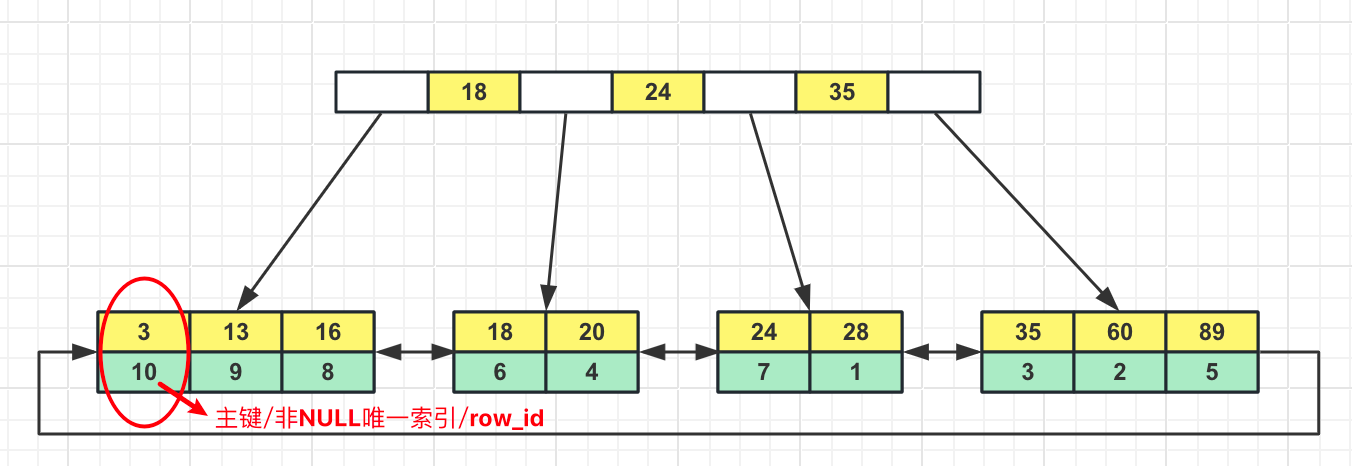
为什么建议InnoDB表一定要建主键
InnoDB表的ibd文件是用B+树来组织存储的,如果表有主键,默认会用主键索引创建聚集索引;如果表没有主键,会用第一个非NULL唯一索引创建聚集索引;如果都没有,会创建一个隐藏列row_id创建聚集索引,以组织存储所有数据。
创建InnoDB表时建主键,既提供了一个操作记录的唯一标识,也可以避免创建隐藏列,白白浪费空间。
为什么推荐使用整型的自增主键
在聚集索引树中定位某个索引的过程中,需要不断地比较索引的大小,使用整型主键比较大小的效率高,并且整型占用空间小。
B+树索引元素是排好序的,插入非自增索引需要进行索引的重新排序,并且会导致频繁的节点分裂(页分裂)和索引树的再平衡,效率较低
联合索引和最左匹配原则
实际工作中,一般不建议建太多单值索引,应尽量使用联合索引(也叫复合索引),它是由多个字段组成的一个索引:
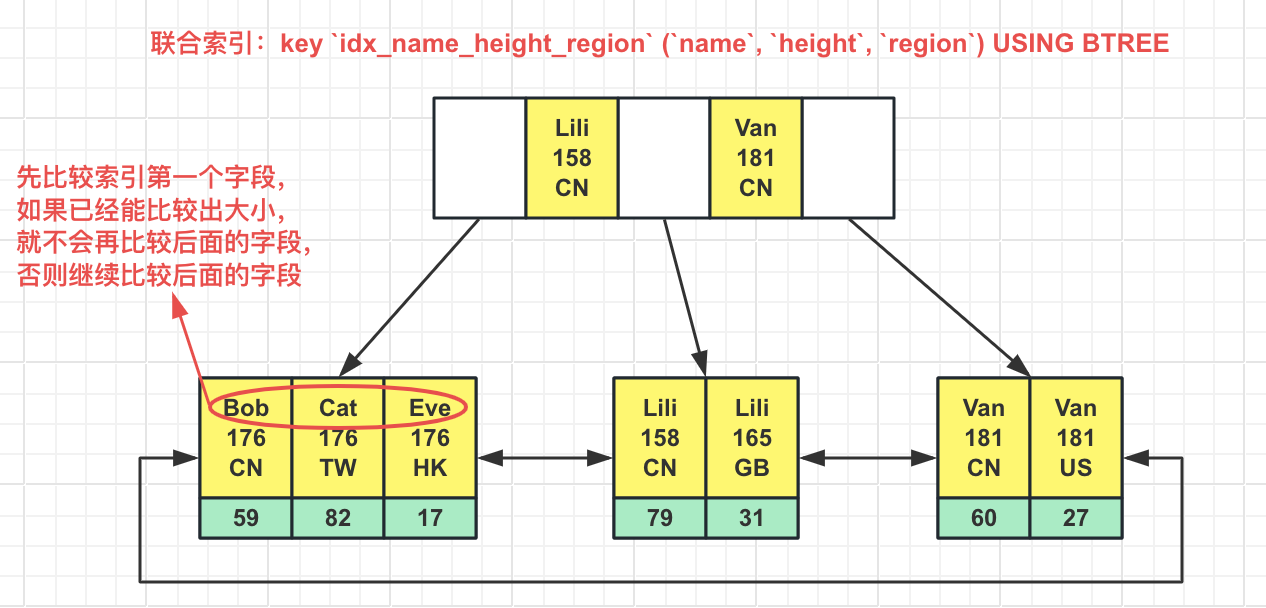
根据上图联合索引的存储结构,可知如果SQL用到的字段跟联合索引从左起的字段连续一致,则可以走联合索引,这就是联合索引的最左匹配原则。根据最左匹配原则,可以轻易判断下面的SQL是否会走索引:
select * from where name = 'Lili' and height = 165:走索引select * from where name = 'Van' and region = 'CN':只有name可以走索引select * from where name = 'Van' and height > 180 and region = 'CN':只有name和height可以走索引select * from where height = 180 and region = 'CN':不走索引