InnoDB B+ 树索引
InnoDB 索引
使用索引,可以帮助我们更快地在表中查找到想要的数据。我们通过这篇文章来学习下 InnoDB 的索引,下面对索引的介绍都将围绕这张表展开:
create table index_demo (
c1 int,
c2 int,
c3 char(1),
primary key(c1)
) engine=innodb default charset=utf8 row_format=dynamic;
-- 数据
INSERT INTO index_demo VALUES(1, 4, 'u'), (3, 9, 'd'), (4, 4, 'a'), (5, 3, ‘y’), (8, 7, 'a'), (10, 4, ‘o’), (12, 7, ‘d’), (20, 2, ‘e’), (100, 9, ‘x’), (209, 5, ‘b’), (220, 6, ‘i’), (300, 8, 'a'), (320, 5, ‘m’); 为了更容易理解 B+ 树索引,我们把 index_demo 表的行格式简化一下,只看我们关心的内容:

回忆下 record_type 属性:
InnoDB 有两类索引:聚簇索引和二级索引,下面详细介绍它们:
聚簇索引
聚簇索引(Clustered Index,也叫聚集索引或主键索引),是按照表的主键构造的一棵 B+ 树,它有以下特点:
页内记录按照主键大小排序成一个单链表
每一层的页都会组成一个双链表
叶子节点存储完整的用户记录(在 InnoDB 中,聚簇索引就是数据的存储方式,即:索引即数据,数据即索引)
InnoDB 会自动给每张表创建聚簇索引。
先看下聚簇索引的简化版数据页:
.png)
下面是 index_demo 表的聚簇索引示意图:
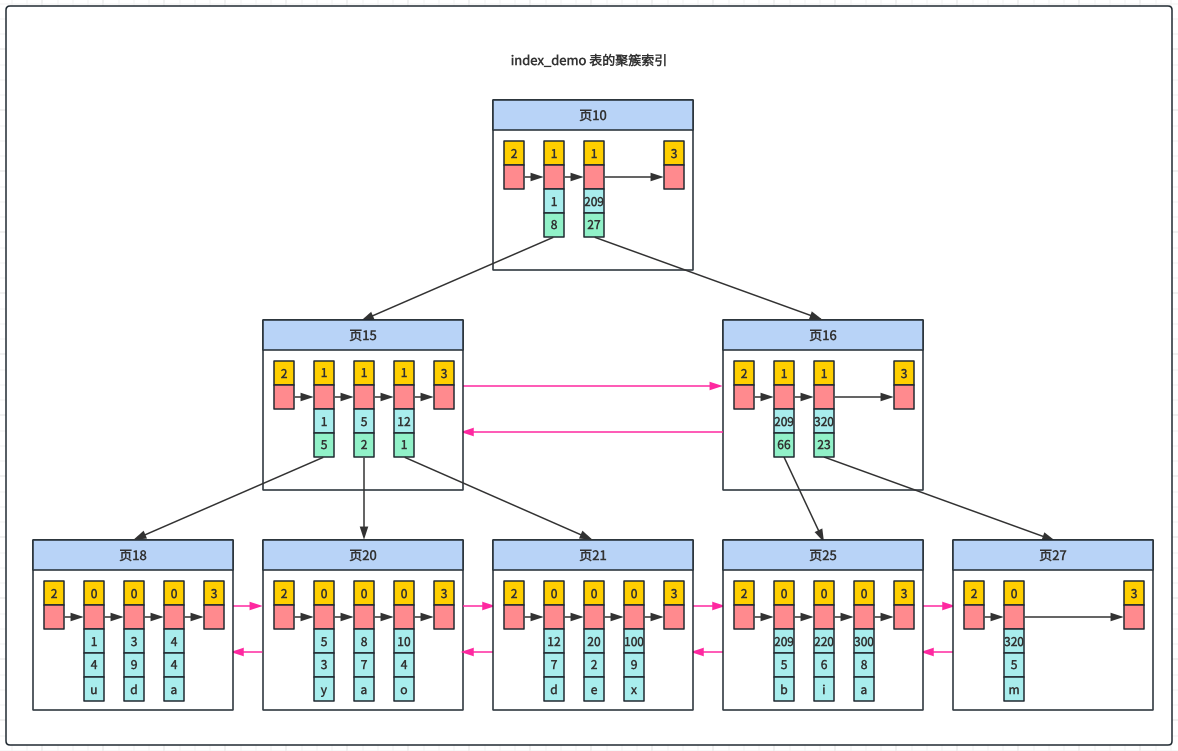
二级索引
二级索引(Secondary Index,也叫辅助索引或非聚簇索引或非聚集索引),是按照表的非主键列构造的一棵 B+ 树,它有以下特点:
页内记录按照主键大小排序成一个单链表
每一层的页都会组成一个双链表
叶子节点不会存储完整的用户记录,而是索引列+主键列,这里是 c2 列 + 主键
由于叶子节点不存储完整的用户记录,因此如果二级索引找到的数据不能满足我们的查询要求,还要带着在二级索引找到主键值回到聚簇索引中取出需要的数据,这就是回表。
先看下二级索引的简化版数据页:
.png)
下面是 index_demo 表 c2 列二级索引示意图:
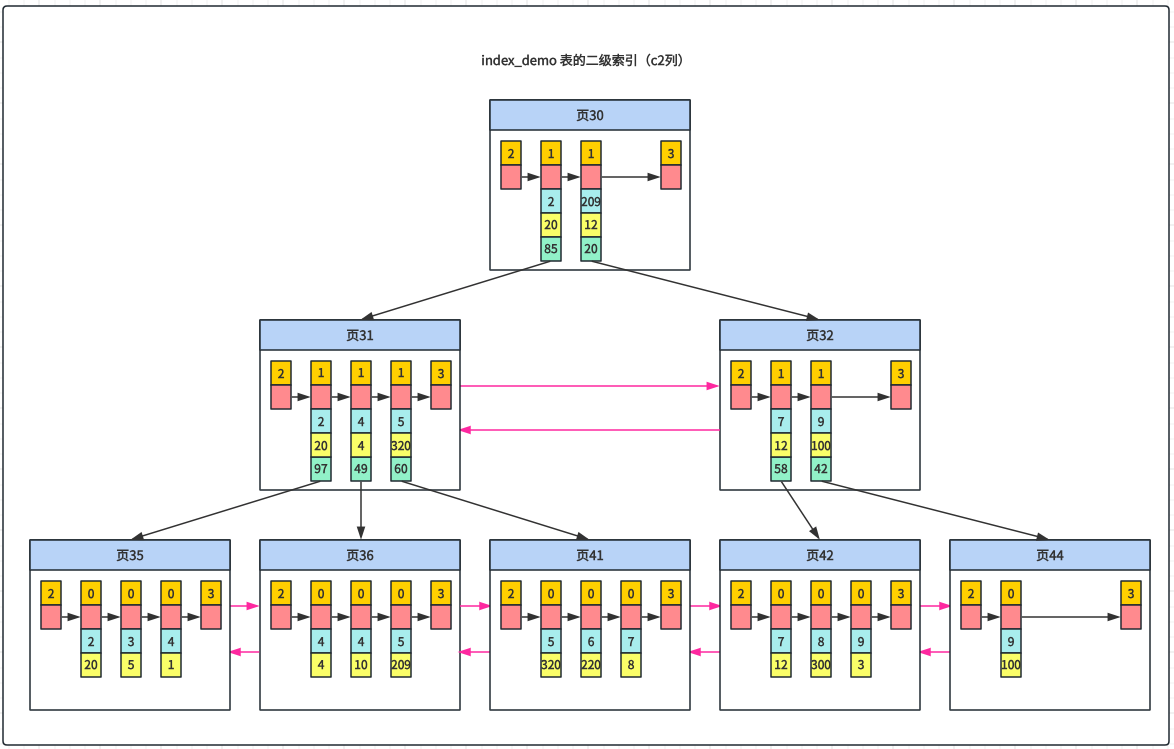
联合索引
我们可以为多个列创建一个索引,这种索引被称为联合索引,本质上还是二级索引。
比如,我们可以给 c2 和 c3 列创建一个索引:idx_c2_c3(c2, c3),这个联合索引的排序规则为:
先按照 c2 列排序
如果 c2 列相同,再按照 c3 列排序
区别于为多个列分别创建索引,这个表示创建多个单列索引,对应多个索引树,而联合索引是一个索引!
计算 InnoDB 表可存储记录数
计算规则:叶子节点可以存储 R 条记录,非叶子节点可以存储 C 条目录项,则一棵 L 层的 B+ 树可以存储的记录数为:R * C(L - 1)
假如 R = 20,C = 1000,L = 3,则可以存储的记录数为:20 * 1000(3 - 1) = 20000000,即 2000 万条。
假如 R = 20,C = 1000,L = 3,则可以存储的记录数为:20 * 1000(4 - 1) = 20000000000,即 200 亿条。
根据上面的计算,可知一般 3 层或 4 层的索引树就够用了。