如何更好地使用 InnoDB 索引
索引的代价
我们已经知道使用索引可以加速我们对表中数据的查找过程,但是索引并不是创建得越多越好,而要要遵循一定的规则来创建。
具体来说,创建和维护索引会有空间和时间上的代价:
(1) 空间代价
每个索引都对应一棵 B+ 树,对于记录数很大的表,每多创建一个索引,就会多占用很大的一块空间。
(2) 时间代价
每次对表进行增、删、改操作时,会对索引中已经排好序的记录和页造成破坏,因此需要花费额外的时间来做记录的移位、页分裂、页回收等操作。如果随意地创建很多索引,每次增删改可能涉及修改的索引树就越多,造成增删改的性能很差。
一般最佳实践是在一张表上创建 3 ~ 4 个索引,并且尽量创建联合索引。
索引的适用条件
create table person_info (
id it not null auto_increment,
name varchar(100) not null,
birthday date not null,
phone_number char(11) not null,
country varchar(100) not null,
primary key (id),
key idx_name_birthday_phone_number (name, birthday, phone_number)
) engine=innodb default charset=utf8 row_format=dynamic;这张表会创建两个索引,一个聚簇索引,一个 idx_name_birthday_phone_number 索引。
为了更容易理解,我们简化 idx_name_birthday_phone_number 索引树,省略页号、记录的额外信息等信息,如下图所示:
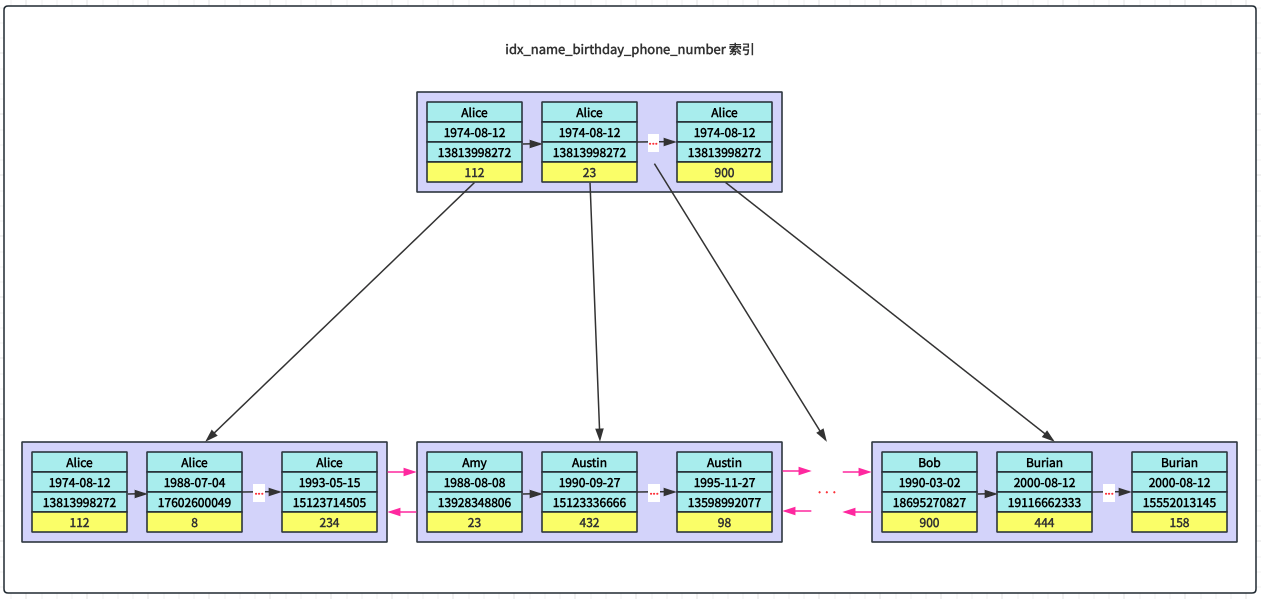
全值匹配
如果查询条件和索引列完全一致的话,就称这种情况为全值匹配,这种查询可以利用索引来快速定位数据行,如:
select * from person_info where name = 'Austin' and birthday = '1995-11-27' and phone_number = '13598992077';由于 MySQL 有一个优化器,因此这几列出现的顺序跟索引列顺序不一致不会影响全值匹配。
匹配左边的列
我们的查询条件中没有包含联合索引全部的列也可以走索引,只需要包含联合索引左边连续的列就行,这种情况也称为最左匹配,如:
select * from person_info where name = 'Austin';
-- 或者
select * from person_info where name = 'Austin' and birthday = '1995-11-27';注意,必须包含联合索引左边连续的列,中间不能跳过一部分列,如下面这个 SQL 就不符合最左匹配原则:
select * from person_info where name = 'Austin' and phone_number = '13598992077';匹配列前缀
字符串比较大小是从第一字符往后逐字符比较的,因此利用字符串索引列的前缀也可以走索引,如:
select * from person_info where name like 'A%'; -- 注意用的 like 关键字,这里表示查询 name 为 A 开头的记录像下面这种列前缀不确定的 SQL 是不走索引的:
select * from person_info where name like '%A%';如果有些场景想要查询某些后缀的记录,可以将该列的值逆序存储,查询的时候就可以用匹配前缀列的方式查询,如想要查询 com 后缀的 url,将 www.baidu.com 逆序存储为 moc.udiab.www 记录,则查询条件为 like 'moc%',
匹配范围值
在索引中,所有的记录都是按照索引值从小到大排好序的,因此可以很方便地使用范围查询,如:
select name from person_info where name like > 'Alice' and name < 'Bob';
上面这个查询的过程是这样的:
首先找到 name 值为 Alice 的记录
然后找到 name 值为 Bob 的记录
所有记录都是通过链表连接起来的,因此只要取出 Alice 记录到 Bob 记录之间的所有记录就好了
注意:如果对多个列进行范围查找,只有第一个索引列可以走索引,后面的列无法走索引,因为后面的列只有在前面的列是相等的时候才是有序的。
精确匹配某一列并范围匹配另外一列
对于联合索引来说,如果左边的列是精确匹配的,后面的第一个范围查询也可以走索引,如:
select * from person_info where name = 'Austin' and birthday > '1995-11-27' and phone_number < '13598992077';
-- 以及
select * from person_info where name = 'Austin' and birthday > '1995-11-27' and phone_number = '13598992077';上面这两个 SQL 的 name 和 birthday 可以走索引,phone_number 都不能走索引。
排序
我们经常需要通过 ORDER BY 查询排序后的记录。通常,InnoDB 会把符合查询条件的记录加载到内存中进行排序,如果符合查询条件的结果集太大以致无法在内存中排序,会使用磁盘来存放排序的中间结果,最后把所有排好序的数据返回客户端。这种在内存或者磁盘中进行排序的方式称之为文件排序(filesort),效率会比较低。理想的话,最好让 ORDER BY 子句用到索引列,这样效率就会很高,如:
select * from person_info order by name, birthday, phone_number limit 10;这个 查询的结果集会先按 name 排序,如果 name 相同,再按 birthday 排序,如果 birthday 也相同,最后按 phone_number 排序,这个排序过程跟 idx_name_birthday_phone_number 索引的排序方式完全一致,因此可以直接从索引中取出排好序的数据,效率相当高。
对于联合索引,ORDER BY 后面的列的顺序也要和联合索引的列顺序一致,下面是一些联合索引排序的例子:
order by phone_number, birthday, name:与联合索引的列顺序不一致,排序无法走索引order by name或order by name, birthday:最左匹配,排序可以走索引where name = 'Austin' order by birthday, phone_number:联合索引前面连续的列精确匹配,后面连续的列排序可以走索引
无法使用索引进行排序的几种情况
asc 和 desc 混用(注意:order by name desc, birthday desc 是可以走索引的)
where 子句用到的列不在排序用到的联合索引中
排序用到的列来自不同的索引
排序用了复杂表达式,如函数 order by UPPER(name)
分组
有时候我们会做一些查询一些统计信息,会用到 GROUP BY 分组操作,如:
select name, birthday, phone_number, count(*) from person_info group by name, birthday, phone_number;上面这个 SQL 的分组过程是这样的:
先找出所有符合查询条件的记录,按照 name 进行分组,将 name 值相同的分到同一组
接着在每个 name 值相同的组内,按照 birthday 进行分组,将 birthday 值相同的分到同一组
最后在每个 birthday 值相同的组内,按照 phone_number 进行分组,将 phone_number 值相同的分到同一组
可以发现,整个分组顺序和 idx_name_birthday_phone_number 索引列的顺序是一致的,因此可以直接使用该索引进行分组。
覆盖索引
当一个查询使用二级索引,但索引中的数据不包含所有需要的列时,InnoDB 会拿着从二级索引查到的主键值返回聚簇索引再去查找所有需要的数据,这就是我们常说的回表。
注意:当回表的数据量很大时(如回表的记录占全表记录的 90% 以上),查询优化器评估查询成本后可能会选择全表扫描。
回表操作的性能不太好,因此我们要尽可能使用覆盖索引,也就是只查询一棵索引树就可以获取所有需要的数据。比如,下面这两个 SQL 都使用了覆盖索引:
select name, birthday from person_info where name = 'Austin';
select name, birthday, phone_number from person_info order by name, birthday, phone_number; -- 排序也优先使用覆盖索引进行查询索引的一些注意事项
只为用于搜索、排序、分组的列创建索引,即 where 子句、order by 子句、group by 子句中的列
只为基数大(区分度大)的列创建索引,可以通过 show index 中的 cardinality 列来判断:cardinality / rows_in_table,这个比值越接近 1,则说明该列越适合创建索引
为了节省空间,索引列的类型应尽可能小(如能用tinyint,就不要用int)
查询时不要在索引列上使用表达式
推荐使用自增主键,目的是尽量避免聚簇索引发生页分裂和记录移位
不要为同一列创建冗余索引